人工智能领域持续高歌猛进,近日两大重磅发布再次引发行业瞩目! Anthropic 强势推出 Claude 3.7 Sonnet,号称其 迄今最智能模型,并创新性地采用 “混合推理” 架构,同时发布 Claude Code 命令行工具,赋能开发者更高效的 AI 编码体验。 与此同时,DeepSeek 开源周再传捷报,发布 DeepEP 通信库,为 MoE 模型训练和推理提供强劲动力! 两大技术突破,预示着 AI 模型正朝着 更智能、更高效、更易用 的方向加速演进!
Anthropic Claude 3.7 Sonnet:首款混合推理模型,智能跃升,编码能力全面领先!
Anthropic 最新发布的 Claude 3.7 Sonnet 模型,可谓亮点十足,最引人注目的莫过于其 “混合推理” 理念。 与市场上其他推理模型不同,Claude 3.7 Sonnet 并非将推理能力独立于通用 LLM 之外,而是将其 整合为模型的核心能力。 Anthropic 认为,正如人类大脑既能快速反应,又能深度思考,AI 模型的推理能力也应是 综合性的、无缝衔接 的,而非割裂的。
“混合推理” 架构:快速响应与深度思考自由切换
Claude 3.7 Sonnet 的核心创新在于,它 既是通用的 LLM,也是强大的推理模型。 用户可以 自由选择 模型的运行模式:
- 标准模式: 作为 Claude 3.5 Sonnet 的升级版,模型以 更快的速度 给出答案,适用于日常对话和快速信息获取。
- 扩展思考模式: 模型在回答前进行 更长时间的 “自我反思”,大幅提升在 数学、物理、指令遵循、编码 等复杂任务上的性能。
更巧妙的是,两种模式下,用户对模型的提示方式几乎完全相同,无需额外学习成本,即可根据任务需求灵活切换。
“思考预算” 精细化控制:速度与质量自由权衡
通过 API 使用 Claude 3.7 Sonnet 时,用户还可以 精细化控制模型的 “思考预算”,即限制模型思考过程使用的 token 数量。 用户可以根据需求,在 速度(和成本) 与 答案质量 之间进行权衡,实现更灵活的应用场景。
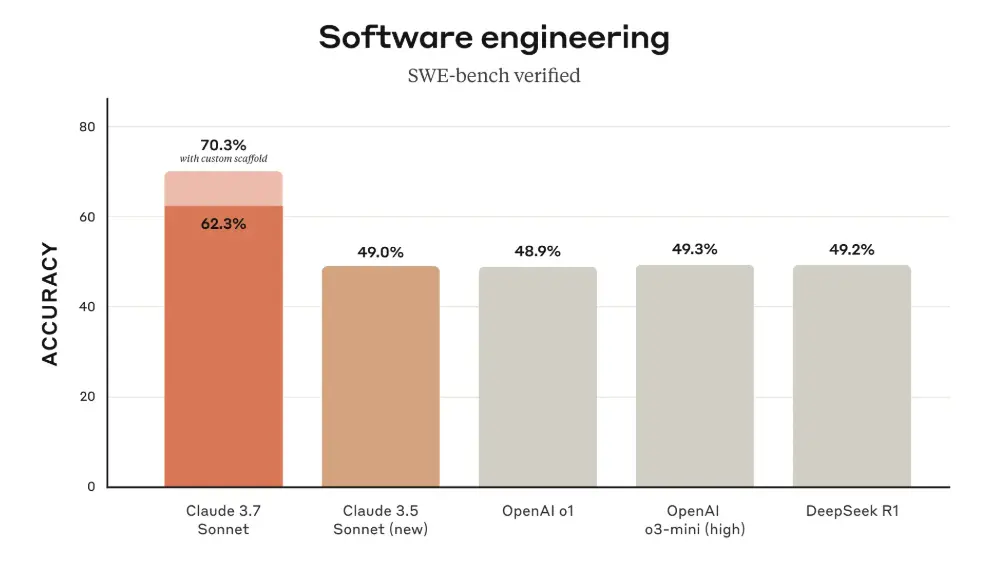
编码能力全面领先:实战表现超越同侪
Anthropic 在开发推理模型时,并未过度追求在数学和计算机科学竞赛题上的极致优化,而是将重点放在 更贴近企业实际应用场景的现实任务 上。 早期测试结果显示,Claude 3.7 Sonnet 在 编码能力方面表现出全面领先的优势:
- Cursor: Claude 3.7 Sonnet 在 实际编码任务中再次名列前茅,在处理 复杂代码库 和 高级工具使用 等方面均有显著提升。
- Cognition: Claude 3.7 Sonnet 在 规划代码更改 和 处理全栈更新 方面,远胜于任何其他模型。
- Vercel: 强调 Claude 3.7 Sonnet 在 复杂代理工作流程中的卓越精确度。
- Replit: 成功部署 Claude 3.7 Sonnet 从头开始构建复杂的 Web 应用程序和仪表板,而其他模型则难以胜任。
- Canva: Claude 3.7 Sonnet 持续生成可用于生产的代码,具有 卓越的设计品味,并 大幅减少错误。
全面支持各版本 Claude 计划,价格保持不变
目前,Claude 3.7 Sonnet 已 全面支持所有 Claude 计划,包括免费版、专业版、团队版和企业版,以及 Anthropic API、Amazon Bedrock 和 Google Cloud 的 Vertex AI。 除免费 Claude 版外,扩展思考模式在所有计划上均可用。
更令人惊喜的是,Claude 3.7 Sonnet 在标准模式和扩展思考模式下的 价格与其前代产品 Claude 3.5 Sonnet 完全相同,保持了极高的性价比。
DeepSeek 开源 DeepEP 通信库:MoE 模型训练推理效率再提升
DeepSeek 开源周持续发力,第二日宣布推出 DeepEP,首个 用于 MoE (Mixture-of-Experts) 模型训练和推理的开源 EP (Efficient Parallel) 通信库。 DeepEP 旨在解决 MoE 模型训练和推理过程中的通信瓶颈,提升效率,降低延迟。
DeepEP 核心特性:
- 高效优化的 all-to-all 通信: 提供高性能的 all-to-all 通信机制,优化数据交换效率。
- NVLink 和 RDMA 全面支持: 节点内 和 节点间 均支持 NVLink 和 RDMA 高速互联技术,充分利用硬件加速能力。
- 高吞吐量内核(训练和推理预填充): 针对训练和推理预填充任务,提供 高吞吐量内核,加速模型训练和预处理速度。
- 低延迟内核(推理解码): 针对 延迟敏感的推理解码 任务,提供 纯 RDMA 低延迟内核,最大程度降低延迟,提升实时性。
- 原生 FP8 调度支持: 原生支持 FP8 数据格式,提升计算效率,降低显存占用。
- 灵活的 GPU 资源控制: 提供 灵活的 GPU 资源控制,实现 计算 – 通信重叠,进一步优化资源利用率。
针对非对称域带宽转发优化,契合 DeepSeek-V3 架构
DeepEP 针对 非对称域带宽转发 进行了专门优化,例如将数据从 NVLink 域转发到 RDMA 域。 这些内核提供 高吞吐量,使其 非常适合训练和推理预填充任务。 此外,DeepEP 还支持 SM (Streaming Multiprocessors) 数量控制,用户可以根据实际需求灵活调整 GPU 资源分配。
低延迟内核助力推理解码,Hook-based 重叠方法优化资源利用
对于 延迟敏感的推理解码 任务,DeepEP 包含一组 纯 RDMA 低延迟内核,最大程度降低延迟,提升实时性。 该库还引入了一种 hook-based 通信计算重叠方法,在 不占用任何 SM 资源 的情况下,实现通信和计算的并行执行,进一步提升资源利用率。
最后总结:AI模型持续进化,软硬件协同发展共筑AI未来
Anthropic Claude 3.7 Sonnet 的发布,展现了 AI 模型在 智能性和易用性 方面的持续进步, “混合推理” 架构和 “思考预算” 控制等创新设计,为用户提供了 更强大、更灵活 的 AI 工具。 DeepSeek DeepEP 的开源,则体现了 AI 基础设施领域的不断完善, 高性能通信库 的出现,将 加速 MoE 模型的训练和推理效率,推动更大规模、更复杂 AI 模型的研发和应用。 软硬件协同发展,共同推动 AI 技术不断向前迈进,为各行各业带来更深远的影响。
购买/下载遇到问题?可联系
闲鱼名称:三点水帅哥
客服邮箱:382813125@qq.com
安装、使用问题,请先查看:技术支持说明
本文由 wpwdbfg 创作,采用 知识共享署名4.0 国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为: Mar 28, 2026 at 02:18 am